Practical Abstract Syntax Trees: A course for refactoring at scale

Spencer Miskoviak
December 7, 2021

Photo by Jan Huber
A few weeks ago, my first course covering Practical Abstract Syntax Trees was released on the newline platform after nearly a year of work. Much of this was based on years of experience working with codemods, linters, and other custom scripts to maintain and refactor large codebases.
Now that the course is live, I wanted to share a bit about why I created this course, what it is, and a few details about the process.
Why this course?
There were a number of motivations for creating this course.
First, I think abstract syntax trees (ASTs) are an underappreciated tool in maintaining and refactoring large codebases. As a result, many of my latest blog posts have centered around ASTs. Hopefully they provide helpful content and introduce more people to the many practical uses of ASTs. Taking this a step further and creating a course felt like the next logical step.
Second, I thought I had a unique perspective initially learning about ASTs as part of a computer science curriculum. Originally, I quickly discarded them as something reserved only for academia or complex compilers. Only later did I rediscover them as a very practical tool to have in the toolbox for working in large codebases. This change in reference point changed my opinion. I wanted a course that focused on this practical perspective.
Finally, I wanted to deepen and solidify my own knowledge around ASTs. As the saying goes, the best way to master something is to teach it.
What is the course?
While the course is focused on the practical uses for ASTs, it's hard to jump right in without first defining some general concepts and a little bit of theory. This course is aimed at folks with an understanding of JavaScript, but assumes no existing knowledge of ASTs.
Therefore, the first module starts with the basics of defining what ASTs are and exploring what they look like. This includes understanding tree data structures, how they relate to compilers, and starting to look at real ASTs with AST explorer.
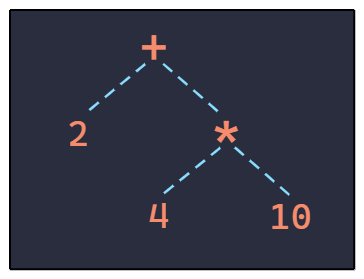
The second module begins covering the available tools for working with ASTs in the frontend ecosystem. The good news, there are many great tools that can do the majority of the heavy lifting. The bad news, many assume existing knowledge of abstract syntax so the documentation can be confusing without that base knowledge. This is why the first module is critical to first understand the general concepts to make these tools and their documentation more understandable and approachable.
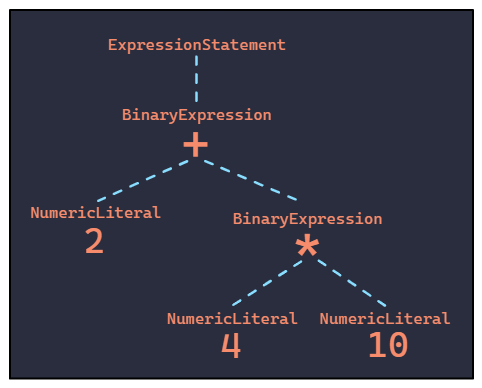
With an understanding of ASTs and the tooling, the remaining three modules focus on a 3-step refactoring example. All three steps rely on ASTs:
- Code audits: statically analyze the code to understand the current state of the codebase to inform the refactor. This is primarily done with babel.
- Codemods: transform the code from the current state to the desired state. This again starts with babel, but then covers jscodeshift, a specialized codemodding tool.
- Linting rules: create rules that code must follow to prevent the previous code pattern from appearing again in the future. This too starts with building a custom rule with babel to establish the basics, but then covers ESLint, a specialized linting tool with support for custom rules.
By the end of the course, the idea is you have a general understanding of how ASTs work and the flexibility they offer to work with code in a generic and reliable way in many different types of work.
Building the course
I went into this knowing creating a course would be a lot of effort. However, I will admit it took longer than I originally anticipated. Regardless, creating the course was a worthwhile experience and I feel the course embodies my original motivations.
The following sections cover the major steps for creating this course. In reality, many of these steps weren't discrete but rather overlapped, repeated, or were constant throughout the process. For example, each step included several rounds of editing, even though it's listed once.
Research
Before writing anything, the first step was to do some basic research to understand the general frontend AST ecosystem: packages, tools, content, other courses, etc. This research helped guide the initial structure of the course, story, and the specific tooling that would be covered.
Sample codebase
Many courses set out building a project from scratch. For this course, applying many of the AST uses in practice require an existing codebase. Before even beginning on the course I created a small sample app with some code duplication that needed to be abstracted. This sample codebase is used in the later modules for the refactoring examples.
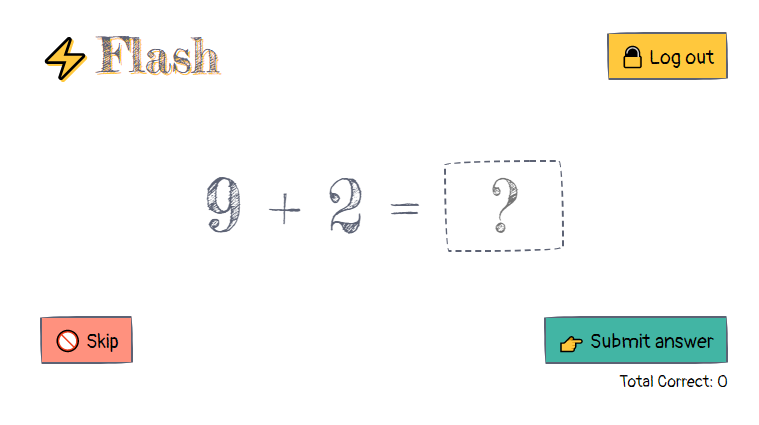
The course itself doesn't cover building this sample app, only refactoring it. Many parts of it like sign up and log in are stubbed out, but it's otherwise a fully-interactive, basic flash card app. I also considered using an existing open source codebase for the refactoring examples but didn't want to introduce additional complexity. This sample codebase is relatively simple to understand and also contains an ideal refactoring example that won't change over time. An open source project might not have as clear refactoring examples and will continue to change over time.
Code
The next step was to create all of the code for each lesson. This started with the basics of ASTs and tools to generate them. Later lessons then build on these concepts to demonstrate how they can be applied in practice.
Starting with the core code helped shape the overall story I was hoping to tell. This included many changes to the module and lesson structure.
Throughout this process I would leave comments in the code and notes about important pieces to explain in more detail. Between revising the course structure and creating notes this provided an outline for the next step.
Content
With the code in place, it was time to translate the code and notes into digestible lessons. Since the code already provided the general structure, determining the overall ideas and sections was straightforward. Most of the time in this step was focused on choosing the right wording to describe some of these more "abstract" concepts.
Editing
After all the code and content was in place, it was time to thoroughly edit and review. As mentioned earlier, editing and reviewing happened constantly throughout each step. However, the bulk of editing was done once the code and content were in place. Once each lesson was completed, I would review it two to three times until I felt like right ideas were conveyed in the right way. Once the full course was completed, I then went through the full course two or three times. This made sure each module and lesson naturally flowed into the next.
Then, I had several friends go through the course and provide feedback, especially around areas of confusion and opportunities to improve the wording. This drastically helped improve the understandability of the course. Finally, an editor from newline also reviewed the full course and provided suggestions and feedback. After this step, the code and content were mostly finalized.
Videos
The last step was to record videos for each lesson that created all the code from scratch, and provided the additional context each lesson covered in video format. Recording, and especially editing the videos was the step that I probably most underestimated. The amount of time it takes to both record and edit is many multiples longer than the final video length. This step was also more straightforward than I had expected by having the code and content already finalized.
Starting with recording videos would've been a daunting task and I likely would've become quickly discouraged. Going in the order of code, content, and videos to slowly build up the course through each step was certainly an effective process.
Releasing
Once the course itself was completed, the final step was releasing it. This required writing a course summary, creating a course landing page, and a few other preparations. The course itself is hosted on the newline platform. The newline team handled the majority of the release and sharing the course with the newline community. Working with newline helped me focus on the core course content, and leave many of these other details to them.
Timeline
From initial thinking to a released course was almost a year. I worked on this course on the side so I had less time to dedicate, but I did work on it steadily a few days a week usually for a few hours. For me, having time to think and reflect on the code or content I had written is important. If I did this again, I don't think I'd try to rush it but rather plan for it taking longer from the start.
Conclusion
While it was more work to create the course than anticipated, I'm really happy with the result. I feel like the course is structured in the way I imagined and achieves many of the original motivations. ASTs can be complex, but I think learning the basics can make them a powerful tool to have in the toolbox for working with larger codebase.
If this topic sounds interesting and you're looking for more to read check out the post about creating a custom transform for jscodeshift or my codemod workflow.
Tags:
course
Practical Abstract Syntax Trees
Learn the fundamentals of abstract syntax trees, what they are, how they work, and dive into several practical use cases of abstract syntax trees to maintain a JavaScript codebase.
Check out the course
